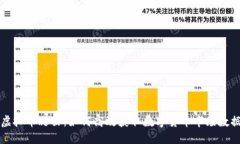
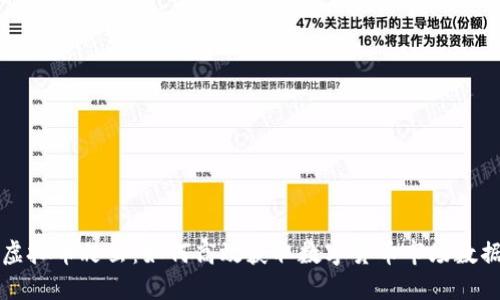
随着区块链技术的快速发展和加密货币市场的不断壮大,越来越多的人开始使用区块链钱包来存储和管理他们的数字...
在如今数字货币市场蓬勃发展的大环境下,虚拟币成为了众多投资者关注的焦点。然而,市场信息的快速变化与数据的庞大酝酿出了一种新的需求,那就是通过爬虫技术获取精确的市场数据。本文将深入探讨虚拟币爬虫的使用及其背后的技术原理。
### 虚拟币基础知识在探讨虚拟币爬虫之前,我们首先需要了解什么是虚拟币。虚拟币是指以数字形式存在的货币,它们不依赖于传统的银行系统,而是基于区块链等技术运作。常见的虚拟币包括比特币、以太坊、莱特币等。虚拟币的运作机制通过技术手段确保交易的安全性和透明度,同时为用户提供匿名性。
在虚拟币市场中,投资者需要随时掌握市场动态,包括价格波动、交易量、市场情绪等信息。这些信息的及时获取往往成为影响投资决策的关键因素。
### 爬虫技术简介网络爬虫,又称为网络蜘蛛,是自动访问互联网并提取信息的程序。随着互联网的发展,爬虫技术逐渐成熟,并被广泛应用于数据分析、市场研究等领域。
爬虫的工作原理主要包括三个步骤:首先是请求目标网页,其次解析网页内容,再将所需数据进行存储和处理。这个过程的效率与稳定性直接影响数据获取的效果。
### 虚拟币爬虫的设计与实现在设计一个虚拟币爬虫时,首先需要明确需求,例如抓取哪些币种、获取哪些数据(价格、成交量等),以及更新频率等。这些需求将决定爬虫的架构与实现方式。

根据需求分析,可以选择适合的爬虫框架和库,如Scrapy、Beautiful Soup等。这些工具可以大大简化爬虫的开发过程,提高开发效率。
数据采集流程通常包括构建请求、处理响应以及提取数据。通过使用API接口,可以更为高效地获取市场数据,减少解析网页时的复杂度。
### 数据清洗与存储在数据采集后,数据清洗是一个必不可少的环节。清洗过程包括去除重复数据、处理缺失值等。有效的数据清洗可以确保后续分析的准确性。
数据存储可以采用多种方式,包括数据库存储(如MySQL、MongoDB)和文件存储(如CSV、JSON)。选择合适的存储方式可以提高数据的检索和管理效率。
### 虚拟币市场数据的分析数据分析可以使用多种工具(如Pandas、Matplotlib等)进行。通过可视化分析,投资者可以更清晰地了解市场趋势,做出科学决策。
市场趋势预测可以通过时间序列分析、机器学习等技术实现。这些技术可以帮助分析历史数据,预测未来价格走势。
### 爬虫的道德与法律问题在进行数据爬取时,爬虫的合法性是一个重要话题。不同网站有不同的爬取策略,侵入性地获取数据可能会触犯法律。
为避免法律风险,建议遵循robots.txt文件中的爬取规范,适度控制请求频率,并在可能的情况下,获得数据提供者的授权。
### 总结与未来展望随着虚拟币市场的持续增长,虚拟币爬虫的应用前景广阔。在投资、市场分析、趋势预测等方面的价值将更加凸显。
爬虫技术在不断更新迭代,投资者与数据分析师应保持对这一领域的持续关注,学习新技术,以适应快节奏的市场变化。
## 相关问题及回答 ### 虚拟币爬虫的工作流程如何?首先,需要明确爬虫的目标,包括要抓取的数据类型、数据来源等。例如,是否需要抓取特定交易所的实时数据?
根据目标,选择合适的爬虫框架和库。常用的框架如Scrapy、Beautiful Soup等,能够支持快速开发。
编写爬虫代码并进行测试,确保能够顺利访问目标网站并正确提取所需数据。同时,测试过程中要注意处理异常情况,例如网站访问失败等。
提取后的数据需要进行存储,选择合适的数据库或文件格式,确保后续分析时数据的完整性和可用性。
进行数据清洗,去除重复数据与无效信息,确保数据的质量,以便于后续的分析与使用。
### 虚拟币爬虫常见的技术挑战有哪些?许多网站对爬虫设置防护措施,如IP封锁、反爬虫策略等,开发者需要找到合适的方法绕过这些防护措施。
虚拟币市场数据的动态变化非常快,如何高效抓取和处理大量数据是一大挑战,需采用多线程或分布式爬虫技术。
抓取的数据可能存在误差和冗余,所以在数据清洗时需要控制数据的质量,以确保后续应用的准确性。
网络连接的稳定性可能影响爬虫抓取数据的效率,合理的重试机制和异常处理可以降低此风险。
在抓取数据时,需遵守网站的爬虫规则与法律法规,以免引发法律风险,这在技术上也是一项重要挑战。
### 如何进行数据分析与可视化?选择适合的数据分析工具,如Python中的Pandas、NumPy等,可以方便地进行数据操作与分析。
结合Matplotlib、Seaborn等可视化库进行图形化展示,使数据分析更加直观,帮助用户识别趋势。
明确需要分析的指标,如市场价格波动、成交量、交易频率等,以便进行针对性分析。
根据数据特点与需求,制定系统的分析流程,包括数据导入、清洗、处理、可视化等环节。
通过分析结果,为用户提供相应的投资建议与决策支持,或者用于进一步的市场预测模型构建。
### 数据清洗的具体流程是什么?在数据采集过程中,容易出现重复数据,因此首要步骤是去除重复项,保证数据的唯一性。
对于缺失的数据,可以通过插补、删除等方法加以处理,确保数据完整性。
在数据清洗过程中,需确保数据格式统一,例如日期格式、货币单位等,以便后续处理。
检查数据中的异常值,利用箱线图、Z-score等方法识别并进行处理,确保数据质量。
必要时,对数据进行转换,例如将类别数据转换为数值型数据,以适应模型分析的要求。
### 如何确保爬虫的数据质量?确保选择的数据源是可靠且常更新的,如知名交易所的API,避免使用不可信的随机网站。
定期对爬虫进行检查与维护,确保能够稳定抓取最新数据,同时适时更新抓取策略以应对网站的变化。
实时监控抓取的数据质量,利用数据概览工具识别异常数据并进行调整,保持数据的准确性。
建立数据反馈机制,根据用户的反馈及市场变化,不断改进爬虫的抓取策略。
对爬虫进行充分的测试,确保其在各种情况下均能正常运行,输出符合预期的数据。
### 虚拟币市场的法律合规问题有哪些?在进行数据爬取时,确认所访问网站的合法性和数据使用政策,以免侵犯他人的知识产权。
在处理用户数据时,遵循GDPR等相关法律法规,确保用户隐私的安全与保护,避免泄露用户信息。
控制访问频率,避免对目标网站造成压力,并遵循robots.txt的规则,合理安排请求时间与频率。
建议在可能的情况下,向数据提供方获取明确的爬虫授权,以防止潜在的法律纠纷。
保持对相关法律法规的关注,通过定期审查与更新自己的爬虫运行策略,最大限度地降低法律风险。
以上内容展示了虚拟币爬虫的全貌及其面临的各种技术和法律挑战。通过对这些方面的深入探讨,读者可以更全面地理解虚拟币爬虫,并为其在数字货币市场中的应用提供参考。

随着区块链技术的快速发展和加密货币市场的不断壮大,越来越多的人开始使用区块链钱包来存储和管理他们的数字...

## 内容主体大纲1. 引言 - 说明OE虚拟币及其重要性 - 提出讨论的目的与意义2. 虚拟币交易的基本概念 - 什么是OE虚拟币...
```### 内容主体大纲1. **引言** - 虚拟币存储的必要性和冷钱包的定义 - 冷钱包与热钱包的区别及优缺点 - 简述冷钱包在...

### 内容主体大纲1. 引言 - 虚拟币的兴起与跑步的结合 - 运动与盈利的新方式2. 什么是通过跑步赚取虚拟币的软件?...